


分析:
评估函数的引入, 为游戏AI提供了理论基础。
- G(s) = a1 * f1(s) + a2 * f2(s) + ... + an * fn(s)
当然机器学习中的随机算法: 模拟退火/遗传算法, 也是有效的方式, 而且其更简单, 也更容易理解, 作者将在这边重点阐释。
遗传算法:
遗传算法(GA)是模拟自然界的进化过程而实现的。物竞天择, 适者生成是其永恒的定律。
首先让我们来定义个体向量(染色体):
- 评估函数各个特征的权重系数构成权重向量 (a1, a2, a3, ..., an), 视为个体向量
1)初始阶段: 选择N个随机值的向量个体
2)互相PK阶段: N个向量互相PK, 获取各自的适应度值
3)进化阶段: 按适应度值排序, 引入淘汰率/变异率等, 进行复制/变异/交叉操作, 诞生新的N个个体
持续迭代2), 3)两阶段, 直到选取合适的个体。
该过程能达到我们的学习需求, 当然我们可以继续做如下优化:
- 引入陪跑员机制: 依经验挑选精英个体, 参加PK阶段, 用于评估个体的适应度, 但不参与进化(复制, 变异, 交叉)过程。
- 按适应值概率进化: 防止群体中极少数适应度高的个体被复制和遗传而达到局部最优解的情况。
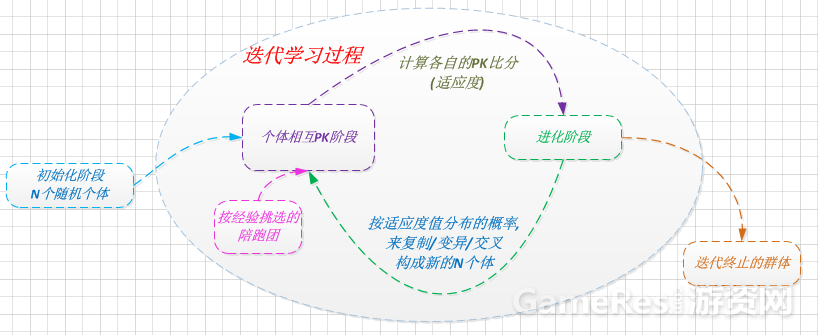
复制/变异/交叉的比率, 以及群体数, 都会影响迭代次数和收敛效果。
小结:
使用遗传算法进行参数学习后, 可以合理地分配权重系数, 那事先说好的特征挑选呢? 简而言之, 通过筛选掉权重系数近似为0的特征即可, ^_^。
二、博弈树优化
启发搜索:
博弈树本质是极大极小的求解过程, 而alpha+beta剪枝则加速该求解过程。
让我们来构建一个简单的alpha+beta剪枝用例: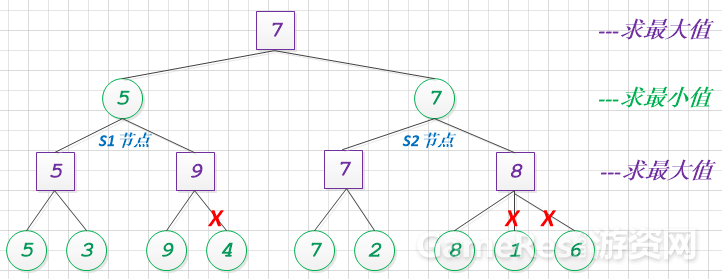
注: 紫色代表极大值求解, 绿色代表极小值求解。
通过人工演算和模拟, 整个博弈过程, 成功地减少了3个节点的计算量的, 效果一般。
这个过程, 我们是否有优化的余地呢? 让我们调整下, 节点S1和S2的搜索顺序。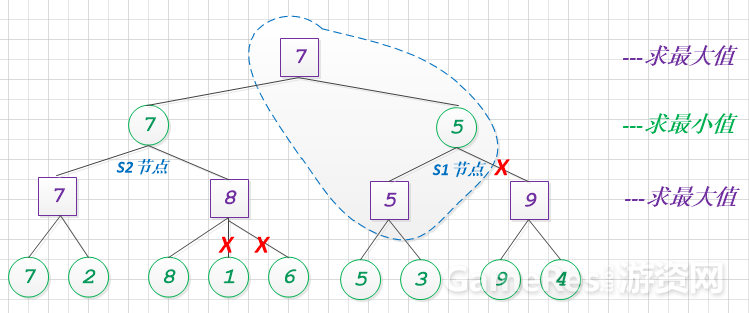
与调整顺序之前相比, 其alpha+beta剪枝的效果提升, 砍去了一个大分支, 减少了4个节点的计算量。
从这个例子中, 我们可以清晰的看到, 对于博弈树而言, 其alpha+beta的剪枝效果, 和搜索顺序是有一定关系的。 简单的总结: alpha+beta效果, 对搜素的顺序敏感。
于是我们找到了一个优化方向: 调整可行步的顺序, 并优先搜索预期高的分支。 该技巧命名为: 启发搜索。 常有人借助历史值, killer步来构造启发函数。
- // 负极大值算法
- int negamax(GameState S, int depth, int alpha, int beta) {
- // 游戏是否结束 探索的递归深度是否到边界
- if ( gameover(S) depth == 0 ) {
- return evaluation(S);
- }
- // 依据预估(历史, 经验)对可行步, 进行排序
- sort (candidate list);
- // 遍历每一个候选步
- foreach ( move in candidate list ) {
- S = makemove(S);
- value = -negamax(S, depth - 1, -beta, -alpha);
- unmakemove(S)
- if ( value > alpha ) {
- // alpha + beta剪枝点
- if ( value >= beta ) {
- return beta;
- }
- alpha = value;
- }
- }
- return alpha;
- }
- return alpha;
- }
- }
- alpha = value;
- }
- return beta;
- if ( value >= beta ) {
- // alpha + beta剪枝点
- if ( value > alpha ) {
- unmakemove(S)
- value = -negamax(S, depth - 1, -beta, -alpha);
- S = makemove(S);
- foreach ( move in candidate list ) {
- // 遍历每一个候选步
- sort (candidate list);
- // 依据预估(历史, 经验)对可行步, 进行排序
- }
- return evaluation(S);
- if ( gameover(S) depth == 0 ) {
- // 游戏是否结束 探索的递归深度是否到边界
- int negamax(GameState S, int depth, int alpha, int beta) {
这边展示了具体的流程, 其效果的好坏, 取决于Hash函数的选择。
简单采用MD5算法, 其实是可行的, 不过比较消耗CPU。 Zobrist hashing算法也是备受推荐。
和记忆化搜索相比, 置换表对应的局面是, 只是中间的预测节点, 因此该状态除了本身和游戏局面相关, 还和当前的搜索深度有关。
因此具体代码可修正如下:
- // 负极大值算法
- int negamax(GameState S, int depth, int alpha, int beta) {
- // 判断状态已存在于置换表中, 且搜索深度小于等于已知的, 则直接返回
- if ( exists(TranspositionTable[S]) TranspositionTable[S].depth >= depth ) {
- return TranspositionTable[S].value
- }
- // 游戏是否结束 探索的递归深度是否到边界
- if ( gameover(S) depth == 0 ) {
- return evaluation(S);
- }
- // 遍历每一个候选步
- foreach ( move in candidate list ) {
- S = makemove(S);
- value = -negamax(S, depth - 1, -beta, -alpha);
- // 保存S到置换表中, 当depth更深时.
- TranspositionTable[S] <= (depth, value) If TranspositionTable[S].depth < depth
- unmakemove(S)
- if ( value > alpha ) {
- // alpha + beta剪枝点
- if ( value >= beta ) {
- return beta;
- }
- alpha = value;
- }
- }
- return alpha;
- }
- return alpha;
- }
- }
- alpha = value;
- }
- return beta;
- if ( value >= beta ) {
- // alpha + beta剪枝点
- if ( value > alpha ) {
- unmakemove(S)
- TranspositionTable[S] <= (depth, value) If TranspositionTable[S].depth < depth
- // 保存S到置换表中, 当depth更深时.
- value = -negamax(S, depth - 1, -beta, -alpha);
- S = makemove(S);
- foreach ( move in candidate list ) {
- // 遍历每一个候选步
- }
- return evaluation(S);
- if ( gameover(S) depth == 0 ) {
- // 游戏是否结束 探索的递归深度是否到边界
- }
- return TranspositionTable[S].value
- if ( exists(TranspositionTable[S]) TranspositionTable[S].depth >= depth ) {
- // 判断状态已存在于置换表中, 且搜索深度小于等于已知的, 则直接返回
- int negamax(GameState S, int depth, int alpha, int beta) {
总结:
启发搜索和置换表, 两者都是很好的思路, 前者通过调整搜索顺序来加速剪枝效果。 后者通过空间换时间。 总而言之, 这些都是博弈树上很常见的优化手段。 当然在具体游戏中, 需要权衡和评估。 下一篇讲讲出于游戏性的考虑, 如何进行优化和策略选择。
相关阅读:对弈类游戏的人工智能设计(1):评估函数+博弈树算法
锐亚教育,游戏开发论坛|游戏制作人|游戏策划|游戏开发|独立游戏|游戏产业|游戏研发|游戏运营| unity|unity3d|unity3d官网|unity3d 教程|金融帝国3|8k8k8k|mcafee8.5i|游戏蛮牛|蛮牛 unity|蛮牛
- 还没有人评论,欢迎说说您的想法!



