

本帖最后由 sunshinezz 于 2015-10-22 10:28 编辑
1.模型需求
存储三维模型的文件,通常需要更高效的空间分配,来尽量减少文件的物理体积。
例如一个模型,可能存有position,uv,normal,tangents ... 等等相关信息。
如果简单的存储为position数组,uv数组,由于这些数组钟可能会有重复数据,因此会造成存储空间的浪费: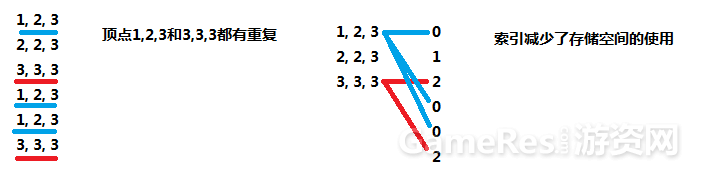
因此,通过使用一个索引数组,可以更高效的利用有限的存储空间。
2.渲染需求
在我们使用底层图形API渲染模型时,首先我们需要将模型读入内存中。
我们了解到,许多模型通过使用索引来节省存储空间,而在渲染模型时,我们需要为API提供完整的三角形数据,所以我们需要还原索引为原始的形式。
这样,某个被周围三角形公用的顶点有可能会有数份相同的数据在内存中,不仅增加了内存的消耗,也增加了渲染时的消耗。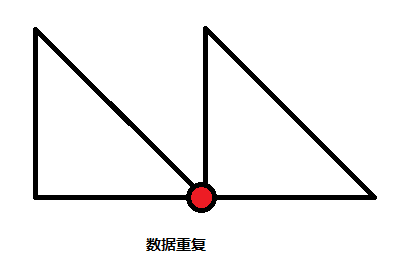
3.解决方案
为了解决模型与渲染需求不一致的问题,我们可以通过在载入模型后,对模型数据进行处理,来使其满足我们的渲染需求。
在Opengl中,可以通过element_array_buffer来进行Indexed Drawing,即通过一个索引,来减少重复数据,减少带宽的消耗。
接下来,只需要从原始顶点列表中,找出那些拥有相同数据的顶点,将其替换为索引,索引到我们的独立定点列表,就可以得到符合渲染需求的数据了。
第一时间,我们会想到使用嵌套循环来查找独立定点数组: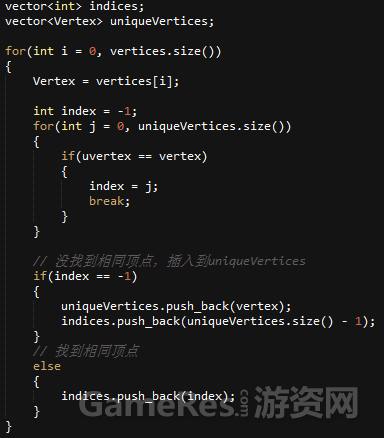
不过很显然,两个嵌套的循环,其中内循环会随着时间的推移而增长,这种方式的CPU消耗非常大。
甚至在发布模式下,处理一个5万顶点的模型都需要几秒钟来完成。
因此我们需要优化其中的内循环,即寻找unique vertex的方法。
如何优化此方法呢?通过查阅知名开源模型解析库Assimp的相关实现,看到了一个非常巧妙的办法。
我们可以通过空间排序来解决这个问题,将曾经需要遍历整个uniqueVertices列表的循环改为一个简单的查询操作。
Assimp的实现逻辑大致如下:定义一个随机平面
- 遍历原始定点列表
- 存储顶点到平面的距离,作为排序的key
- 根据距离对处理的定点列表进行排序
这样,通过这个空间排序的结果,我们可以快速定位到与输入顶点位置接近的潜在相同顶点列表。
通常情况下,此优化得到的潜在相同顶点列表大小不会超过10个,大大提高了数据处理的效率。
将原本需要数万此的循环,减少为数十次,成功的完成了我们的渲染需求。
文/xinhou GAD

锐亚教育,游戏开发论坛|游戏制作人|游戏策划|游戏开发|独立游戏|游戏产业|游戏研发|游戏运营| unity|unity3d|unity3d官网|unity3d 教程|金融帝国3|8k8k8k|mcafee8.5i|游戏蛮牛|蛮牛 unity|蛮牛
- 还没有人评论,欢迎说说您的想法!



